Note: This website was automatically translated, so some terms or nuances may not be completely accurate.
What is the power of "MINUKERU" that uncovers employees' subconscious thoughts from surveys?
What if we could analyze text data like surveys and word-of-mouth with higher resolution and speed?
Dentsu Inc., in collaboration with Professor Sotaro Katsumata of the Graduate School of Economics, Osaka University, has developed "MINUKERU" (*1), a data solution that extracts "context" from text data that is invisible through conventional analysis. It was launched in June 2024 (see the release here ).
This series explores "How far can MINUKERU see into text data?" through case studies.
※1 Dentsu Inc. analyzes the data using MINUKERU and delivers reports on the results to clients. Based on these analysis results, Dentsu Inc. can also develop strategies and action plans.
The Hidden Context Revealed by MINUKERU
We asked employees of a certain engineering company, "What aspects of the company attracted you to join?"
Analyzing the responses (open-ended descriptions) using conventional text mining (※2) produced the following word cloud (where more prominent words appear in larger font). While many potential keywords like "products," "development," "contribution," "atmosphere," and "environment" appear, interpreting the specific context behind why they found the company appealing is quite challenging based on this output alone.
※2 Text mining: A technique that extracts words from text and analyzes their frequency and co-occurrence to derive useful information.

Meanwhile, MINUKERU utilizes a statistical technique called "topic modeling" (*3) to extract multiple contexts from survey responses.
※3 Topic Modeling: A natural language processing technique that identifies topics (subjects) within text data.

Looking at the word cloud for "TOPIC1," the words "atmosphere," "work," and "environment" appear prominently. This suggests respondents were attracted to the "work environment and company atmosphere."
"TOPIC2" features words like "development," "contribution," "tools," and "automotive industry," suggesting an interpretation of "contributing to the automotive industry through tool development."
Similarly interpreting "TOPIC3" and "TOPIC4," the appeal points can be considered "the company's technological and product capabilities within the automotive industry" and "stability and opportunities for self-growth," respectively.
Compared to conventional text mining, this approach makes interpreting context easier. Extracting such latent context is one of MINUKERU's key features.
MINUKERU can analyze any type of text data, but it seems particularly well-suited for questions where the character count per respondent is likely to be higher.
Employee surveys about the company, as mentioned earlier, tend to gather responses that express candid thoughts and opinions, for better or worse, often in somewhat lengthy answers. This makes it easier to extract highly insightful results.
It is also well-suited for analyzing customer feedback received by call centers. Customer voices from call centers can be converted into text data. Since interactions with customers often involve some degree of back-and-forth, the volume of text data per customer is typically high, making it a good fit.
Conversely, data like viewer ratings for commercials, which often consist of short responses like "funny," "boring," or "cool," may be less conducive to extracting highly insightful results.
Capturing Employee Characteristics by Latent Context
A major feature of MINUKERU is its advancement beyond traditional topic models to incorporate quantitative data into analysis (*5). Text data alone can sometimes make it difficult to discern whether emerging contexts are positive or negative. Integrating quantitative evaluations allows for this positive/negative distinction.
Furthermore, even when quantitative data shows similar evaluations (e.g., "Good relationship with supervisor" receives high scores), these can sometimes be divided into several distinct contexts (e.g., "Easy to talk to," "Provides thorough guidance," etc.). MINUKERU enables the extraction of such contextual nuances.
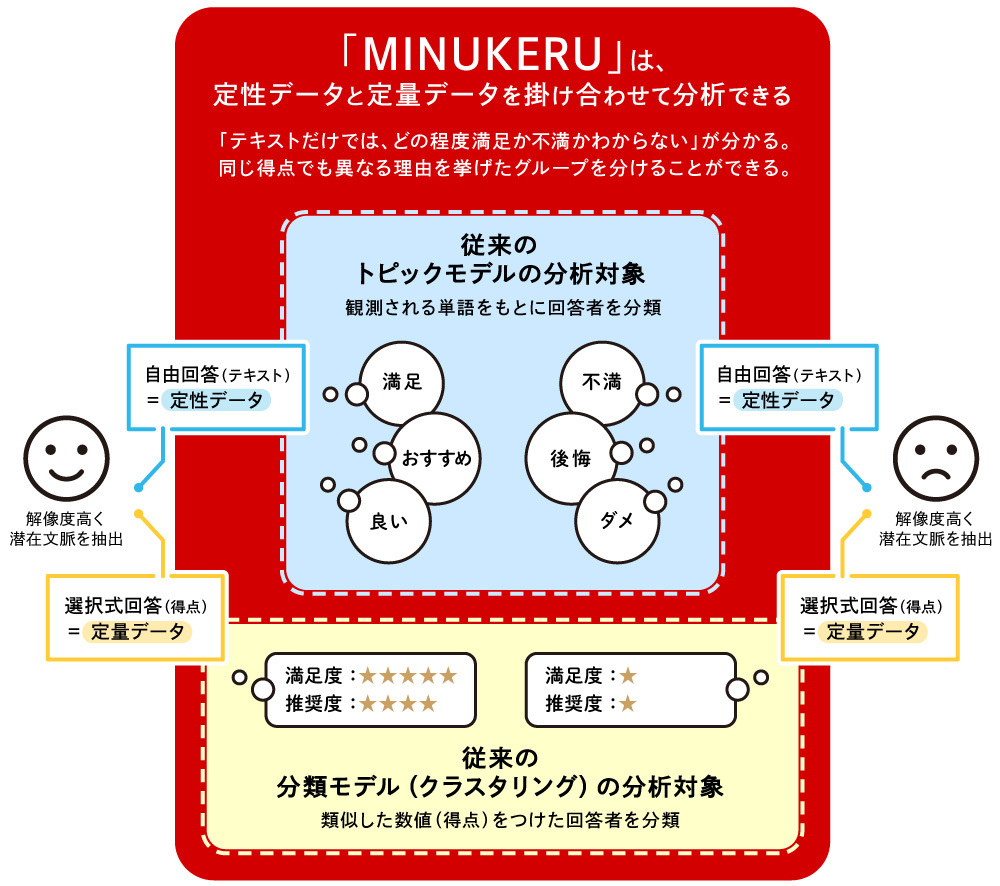
※5 Katsumata, S., & Takahashi, K. (2024, July 27-29). A Combined Topic Model for Unstructured and Structured Data. The 46th ISMS Marketing Science Conference, Sydney, Australia.
Continuing the story of the engineering company survey mentioned earlier. MINUKERU clusters each employee based on qualitative data (in this case, open-ended responses), assigning labels like "Employee A is TOPIC1" or "Employee B is TOPIC3" (*6). This is the key difference from cluster analysis based on quantitative data.
In the engineering company's employee survey, besides open-ended responses, quantitative data was also collected on perceptions of company transparency/atmosphere, autonomy, internal systems, HR systems, and demographics (age, years of service, managerial status).
Using this data, we can evaluate which quantitative items are high or low for people belonging to each TOPIC, and also assess the characteristics of employees belonging to each TOPIC from a demographic perspective. This is essentially equivalent to cross-tabulating quantitative items by cluster in a cluster analysis. The following are the actual results.
*6 Quantitative data is also considered during the clustering process, but due to the complexity of the content, details are omitted here.
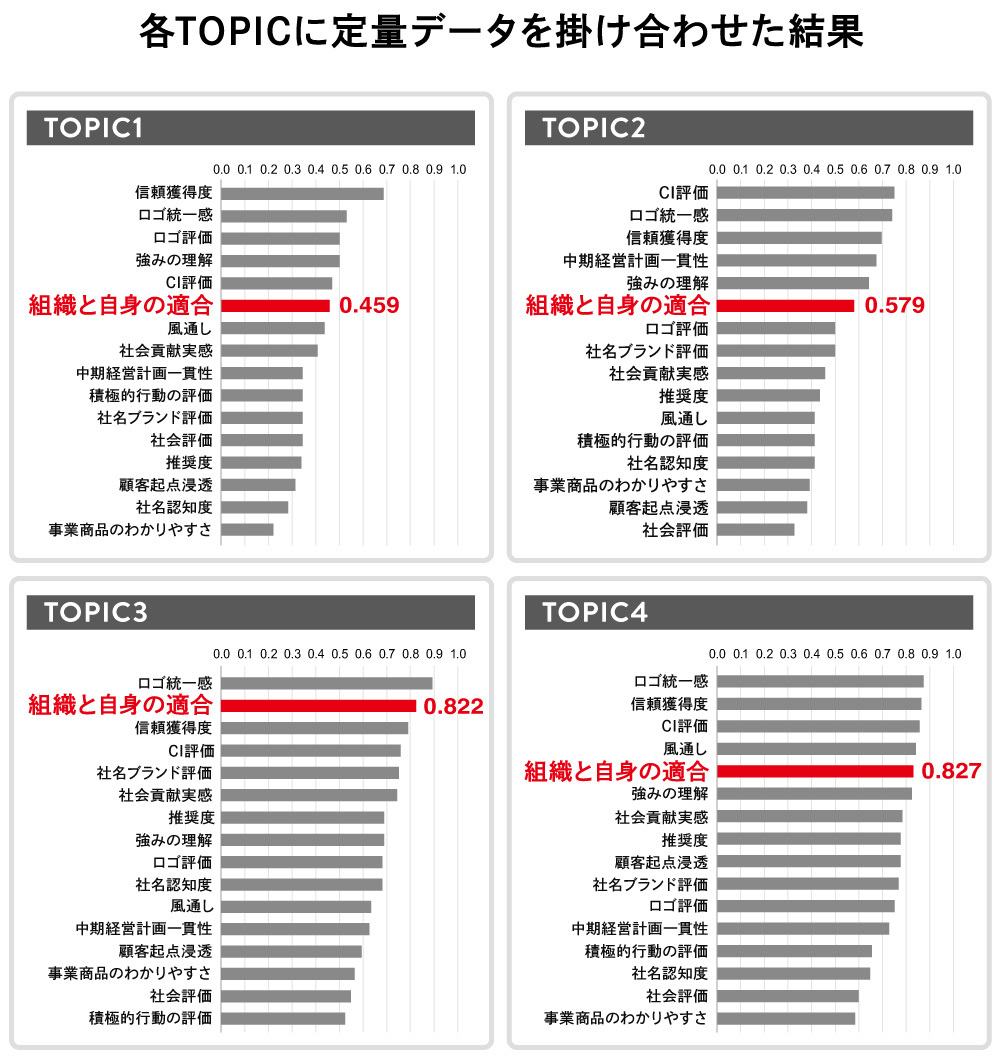
From an employee engagement perspective, the "Organizational Fit" metric is crucial. TOPIC4 scores highest, with TOPIC3 also scoring well. In contrast, TOPIC1 scores lower than other TOPICS and ranks lower in item order.
Seeing these results naturally leads to the question: "What kind of employees belong to each TOPIC?" This survey also collected data on age and years of service, revealing the characteristics of these employees. The results are as follows.
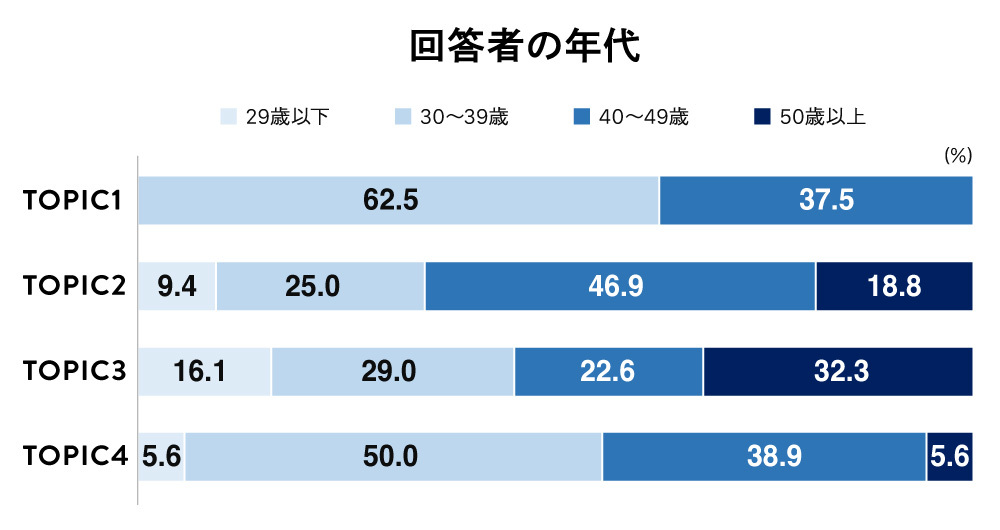
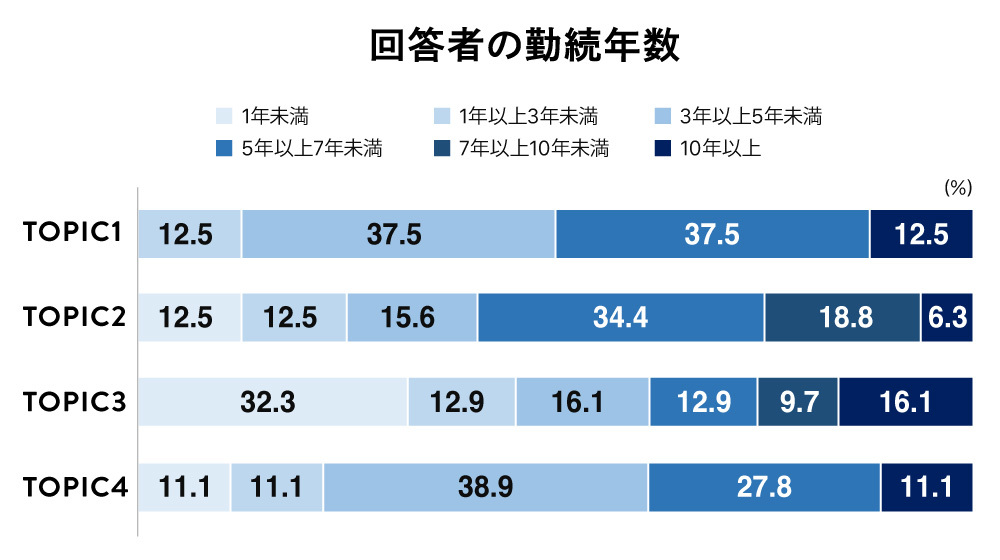
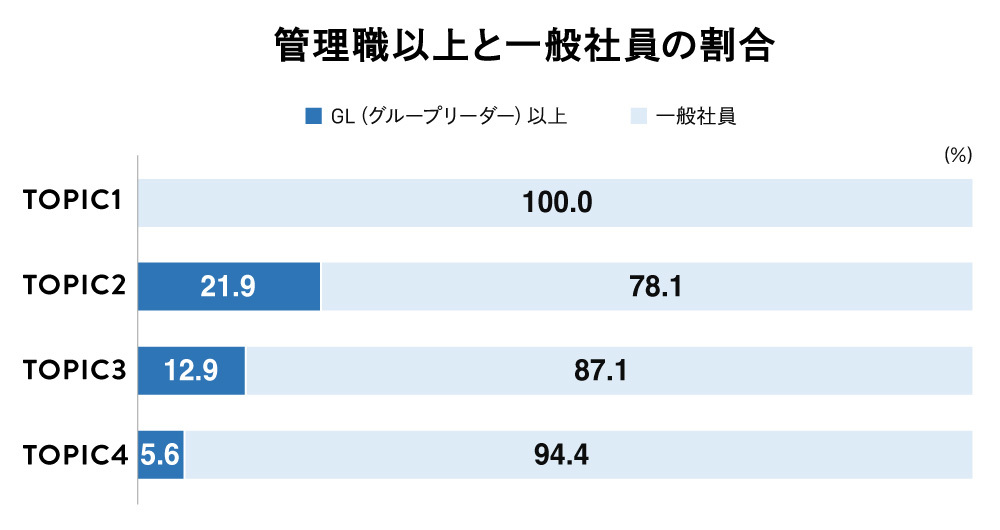
TOPIC1, which showed overall low company evaluations, tended to have more employees in their 30s to 40s, with 1 to 5 years of service – suggesting they are employees who have gradually become accustomed to their roles within the company. We presented these results to the company's Corporate Planning Department. They mentioned that employees leaving after about 3 years are not uncommon, and commented, "We thought these very people were precisely the ones associated with TOPIC1."
Conversely, examining the demographics of employees in TOPIC3 and TOPIC4, which showed high company evaluations, reveals that TOPIC3 has a higher proportion of employees aged 50 and above with 7 or more years of service, including a significant number of managers. TOPIC4 also has longer service tenures, but is predominantly comprised of employees in their 30s and 40s.
This suggests a hypothesis: even within the same age group, longer tenure correlates with higher company evaluation. Therefore, retaining employees with shorter tenure becomes crucial.
While this data doesn't allow us to delve deeply into why engagement contexts differ based on tenure within the same age group, conducting individual employee interviews, for example, could enable further exploration.
This time, we introduced MINUKERU's features by presenting an example of analyzing survey responses from a company. We hope you now understand how high-resolution analysis of text data themes, combined with quantitative data, enables deeper insights into the text content.
For more information about MINUKERU, please contact us at the address below.
Email: minukeru@dentsu.co.jp

Was this article helpful?
Share this article
Newsletter registration is here
We select and publish important news every day
For inquiries about this article
Author

Kazuki Takahashi
Dentsu Inc.
Second Marketing Bureau
Marketing Consultant
Specializing in data-driven solutions (data analysis, data-driven PDCA cycles, etc.), while also engaged in diverse solution provision including corporate/brand consulting, internal branding, vision definition, business/marketing strategy formulation, digital marketing consulting/transformation, sales support, and business development. Ph.D. (Social Engineering).

