Note: This website was automatically translated, so some terms or nuances may not be completely accurate.
Considering the Essence of Advertising Effectiveness with a Causal Inference Researcher

Tomofumi Nakamura
Keio University Faculty of Science and Technology

Nagata Daiki
Dentsu Inc.
In recent years, the demand for verifying the effectiveness of advertising measures has grown significantly. Companies are increasingly asking the tough question, "Is this ad truly effective?" and adopting analyses using data science approaches.
The critical question then becomes the "quality" of the data science. What approaches are necessary to achieve more precise and sophisticated effectiveness verification? In this series, Dentsu Inc.'s Data & Technology Center—which has focused on analysis and solution development using statistics and machine learning alongside in-house data scientists and researchers—will introduce how data science can be leveraged for advertising effectiveness verification.
The first installment features a discussion between Keio University Researcher Tomoshige Nakamura, serving as an advisor, and DENTSU CROSS BRAIN INC.'s Hiroki Nagata on "Advertising Effectiveness Verification Using Causal Inference (*1)", a field Dentsu Inc. has researched extensively for many years.
※1 Causal inference: A method that uses statistical approaches to estimate the effects of initiatives and other factors.
Applying Causal Inference to Estimate Advertising Effectiveness
Nagata: Today, I'd like to discuss the business applications of causal inference, a method gaining significant attention in recent years, with Professor Nakamura, a researcher at Keio University's Faculty of Science and Technology. First, could you tell us about your area of expertise and research focus?
Nakamura: My specialty is statistical causal inference. My primary research focuses on statistical causal inference and machine learning theories like random forests. I also work on applying these theories to healthcare and developing data analysis methodologies.
Nagata: So, you're building on statistical theory to analyze real-world phenomena. Is there anything you consciously focus on in your daily research activities?
Nakamura: Theoretical work often tends to delve into intricate calculations. However, I consciously aim to design simpler methods that can be used by those actually engaged in business, helping them in their decision-making. For an easily understandable example, I've analyzed the effectiveness of bunt and squeeze plays in baseball using statistical causal inference methods.
Nagata: Professor Nakamura's research theme, causal inference, is a method that uses statistical approaches to estimate the effects of interventions like marketing strategies. Causal inference has developed, particularly in medicine and economics, as a method to evaluate the effects of interventions like drug treatments or policy changes. Since this method can also be used to prove the effectiveness of advertising strategies, Professor Nakamura has been supporting our operations as an advisor for over three years, conducting study sessions and joint research.
The Pitfalls Hidden in Simple Lift Effect Verification
Nagata: After developing TV and radio data solutions at Dentsu Inc., I now support client data analysis at DENTSU CROSS BRAIN INC., where I am currently seconded. While I've been involved in data business for many years, I feel there has been a growing demand in recent years for proving the effectiveness of advertising campaigns.
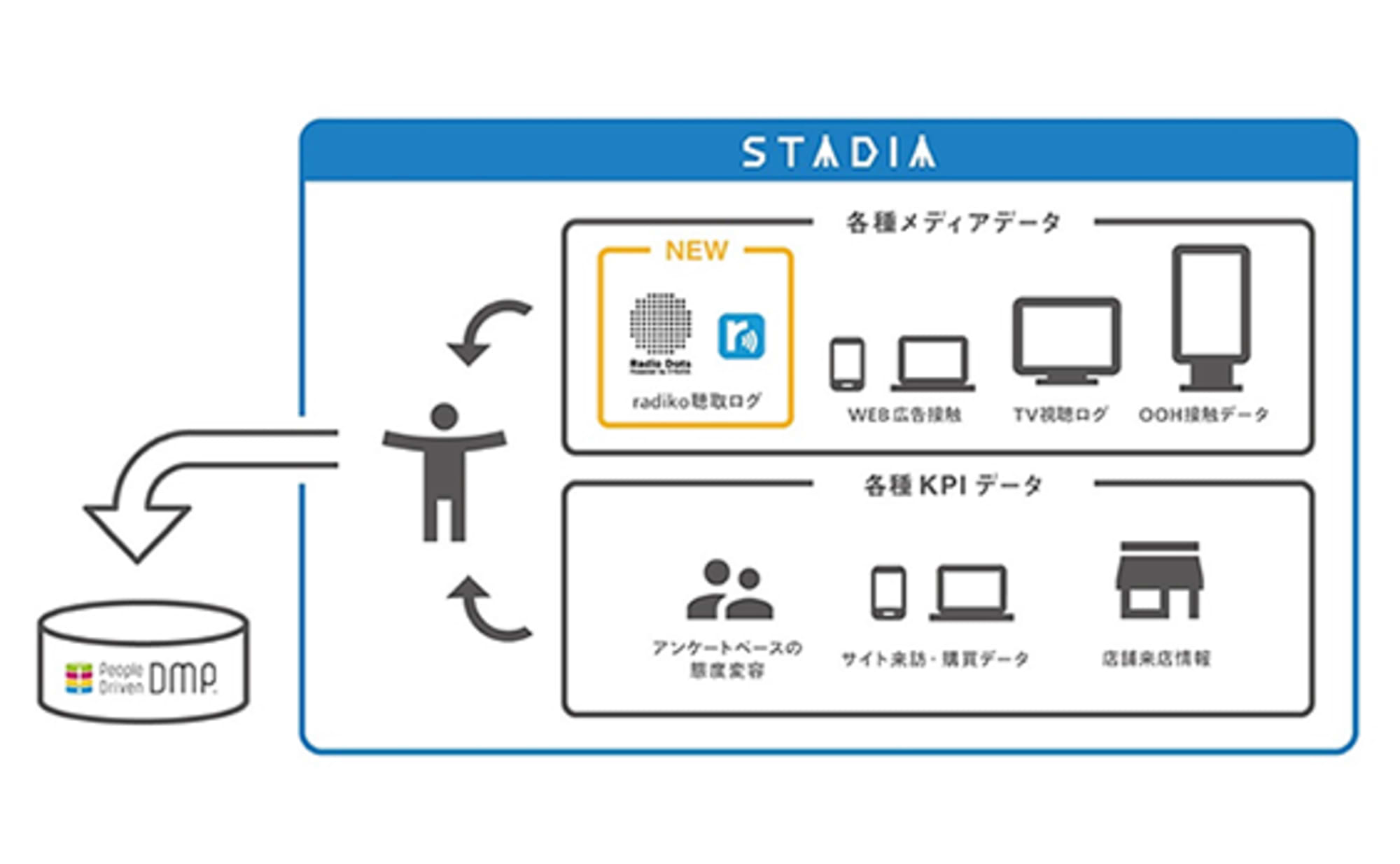
To address this need, we've also sought to enhance the accuracy of our analysis using causal inference concepts, even in solutions like "STADIA," which can analyze the effectiveness of TV commercials using large-scale IoT data.

This chart shows how the KPI (the percentage of users who converted on the campaign site) changed for viewers versus non-viewers of a TV commercial aired by a client during a certain campaign. This type of analysis is also commonly used in brand lift surveys.
At first glance, this campaign appears to show a KPI lift due to commercial exposure. What should we be cautious about when conducting such analyses?
Nakamura: This chart compares two groups: commercial viewers and non-viewers. It's crucial to scrutinize whether the composition of these groups—in terms of age, gender, etc.—is truly uniform and homogeneous. For example, if the commercial viewer group has a higher proportion of older adults, while the non-viewer group has more younger people, the increase in conversion rate might not be due to commercial exposure. It could simply reflect that older adults are more likely to convert in the first place.
Nagata: Indeed, in this case, there seems to be a "bias" between those who saw the commercial and those who didn't. More people are choosing not to access television as a medium, and this trend is particularly pronounced among younger demographics. Considering this, it's reasonable to imagine that those who saw/didn't see the commercial are relatively more likely to be older/younger. In other words, there's an age bias affecting the perceived advertising effectiveness. How should we properly address this?
Nakamura: If conversion rates or commercial exposure time differ by age group, we need to compare by age group or apply weighting to the sample size for correction. It's fundamental: without homogenizing the comparison group, we cannot accurately determine whether a rise in KPIs stems from age bias or the causal effect of the commercial (pure advertising impact).
The Strength of Propensity Scores in Achieving Pseudo-Homogeneity
Nagata: So when comparing two groups, it's desirable to compare as "homogeneous groups" as possible. And in such cases, "causal inference" is an effective method for estimating the causal effect of the commercial. Could you explain in detail why the causal inference approach is effective?
Nakamura: In statistics, there's a method called "randomized controlled trials" (RCT) that suppresses the influence of other variables on the effect being investigated. A famous example is Fisher's experiment. When wanting to study the effect of pesticides on crops, simply dividing a field into two sections—one with fertilizer and one without—wouldn't allow for a homogeneous comparison because the sunlight and drainage conditions would differ between the two. Therefore, by subdividing the field into smaller plots and randomly assigning fertilizer treatment, we can minimize the influence of these variables. Now, can this method be applied to commercials? Randomly assigning whether people see a commercial or not is difficult, right?

Nagata: So, it's practically impossible for us to randomly divide people into two groups, force one group to watch a TV commercial, and prevent the other group from seeing it.
Nakamura: Exactly. Furthermore, when evaluating ad effectiveness, there are a vast number of variables. Age, gender, annual income, savings, TV viewing time, digital activity levels... and various other variables, all of which could potentially influence ad visibility or conversion rates. Even if we could group people with completely matching characteristics from among "many variables," the sample size would become extremely small, making the effectiveness evaluation itself untenable. In situations like this, where homogenizing/perfectly matching comparison groups is difficult, yet we still want to derive causal effects, the causal inference approach becomes effective.
Nagata: Factors like gender or annual income, which can introduce bias beyond age, are often called "covariates." Indeed, when there are many covariates, achieving homogeneity or matching across all variables is challenging. So, what specific countermeasures can causal inference provide?
Nakamura: By utilizing "propensity scores," we aggregate information on various bias factors to achieve homogeneity. A propensity score quantifies the "tendency" of a person to respond to a commercial, for example, by aggregating variables like "45 years old, male, unmarried, annual income of 6 million yen."

The propensity score was proposed in 1983 by Paul Rosenbaum and Donald Rubin. Theoretically, it allows comparison between subjects with the same propensity score, even without fully controlling for all covariates.
Getting a bit technical, specifically, we estimate propensity scores using models like logistic regression (※2) or random forests (※3) from many variables, then match and compare people with the same propensity scores.
Nagata: Essentially, this allows us to estimate something unobserved—the "ease of matching to TV commercials"—using statistical models. From a data analyst's perspective, the major benefit of propensity scores is that they lower the barrier to analysis.
※2 Logistic regression model: A statistical model that formulates the selection probability p using the logistic function.
※3 Random Forest: A machine learning method. A model that learns by integrating the results of generating a large number of weak learners called decision trees.
The essence of propensity scores is to homogenize the comparison group
Nagata: I understand that propensity scores are useful for correcting biases between groups. So, what is the essence of analysis using propensity scores?
Nakamura: As mentioned earlier, in evaluating TV commercial effectiveness, there is almost always a skew in the distribution of covariates like gender or age. Tendency scores counter this skew by applying inverse weighting, effectively equalizing the distributions. This is called "quasi-randomization." Essentially, the core of tendency score analysis is creating two pseudo-homogeneous groups.

Nagata: So, in the TV commercial example, the key point is that the age bias existing between the two groups can be homogenized through propensity score adjustment. Are there any points to be cautious about when performing analysis using propensity scores?

Nakamura: Propensity scores are ultimately values estimated from the data, so we can't be certain they are truly correct. However, we must never forget to verify that weighting the distribution using propensity scores has indeed equalized the distribution of covariates. It's crucial to go through the process of confirming whether age and gender ratios are truly balanced and whether bias has genuinely been removed.
Nagata: That's a surprisingly common stumbling block for data scientists doing causal inference. For those interested in concrete analysis examples, I highly recommend "Iwanami Data Science Vol. 3" (Iwanami Shoten), which Professor Nakamura also contributed to.
Data quality, insight, creativity... What truly matters in the advertising business?
Nagata: Listening to Professor Nakamura's explanation, I got the impression that causal inference requires not only focusing on the fundamental principle of homogenizing comparison groups but also demands meticulous analysis.
Professor Nakamura and Dentsu Inc. have had an advisory contract for over three years now. As we increasingly face client requests for advanced effectiveness verification, consulting with Professor Nakamura to refine my analyses ensures they truly guide sound strategic decisions. This collaboration enables us to deliver proposals at a higher level. From your perspective, Professor Nakamura, what are your thoughts on the current state of the advertising business?
Nakamura: In the advertising business, I believe the bottleneck lies in "data quality." For instance, in healthcare, experiments are designed following ethical processes for research purposes, making the resulting data easier to handle. In contrast, advertising faces challenges like privacy issues preventing certain data collection and difficulties forming appropriate samples, making it impossible to directly apply causal inference theory.
Conversely, I see tremendous potential in the ability of those in advertising to infer interpretations from imperfect data and to generate ideas based on human behavioral principles and various other factors. These outputs are precisely the kind that someone focused solely on theory wouldn't produce. I'm constantly learning how crucial it is in advertising data analysis to fill in the gaps with logic and ideas.
If I could wish for more, it would be for more translator-like individuals who bridge theory and business to emerge in the advertising industry. From a researcher's perspective, this would be immensely reassuring. If more people could stand between researchers and business professionals, appropriately translating each other's language, I believe the speed of development and proof-of-concept experiments would accelerate beyond current levels.
Nagata: The causal inference approach itself isn't confined to specific fields; I find it extremely useful for estimating the effects of implemented measures. Recently, the research by Card, Angrist, and Innes, who won the Nobel Prize in Economics, also drew attention for using a causal inference approach. What direction do you think causal inference research will take from here?
Nakamura: It's been about 40 years since propensity scores were introduced in 1983. Alongside technological advancements, the nature of communication and data has changed significantly. Statistics now utilize AI, while causal inference employs machine learning. The focus of effectiveness verification has shifted from large populations to smaller groups and even individual "people." In healthcare, causal inference aids in optimizing personalized medicine. Regarding advertising, there's a growing need to deliver ads to individuals most likely to convert. Recently, methods like Causal Trees (a causal inference technique using decision trees to estimate individual treatment effects) are being researched as technologies to target ad delivery toward segments with higher advertising effectiveness.
Nagata: I see. So, machine learning identifies whether someone is likely to convert, while causal inference determines how effective an ad will be for them when they see it. It's about finding people who won't buy without a coupon and delivering it to them, rather than giving coupons to those who would buy anyway. That's the essence of maximizing advertising effectiveness, and causal inference feels like a powerful tool for that.
Nakamura: Yes. It's definitely one area we'd like to advance research on together with Dentsu Inc. Furthermore, we aim to develop methods that convey data analysis results more visually, rather than just presenting a list of numbers. After all, theory only has value when it's actually used, so I believe we need to bridge the gap with business more effectively.
Nagata: Mutual understanding is crucial, isn't it? I believe we business people also need to grasp theory to some extent. Sharing a common language will help us build better relationships.
Dentsu Inc. has advocated a people-centric data utilization framework called "People Driven Marketing." I feel approaches like personalized medicine hold potential for application within our business as well. I look forward to the future development of causal inference and hope we can implement new insights into our business. Thank you for your valuable insights today.

Was this article helpful?
Share this article
Newsletter registration is here
We select and publish important news every day
For inquiries about this article
Author
Tomofumi Nakamura
Keio University Faculty of Science and Technology
Researcher
At Keio University, I conduct theoretical development in statistical causal inference and statistical machine learning, as well as applied research on statistical methods for marketing and healthcare fields. Since 2019, I have been engaged in consulting work for Dentsu Consulting Inc.'s advertising business. Ph.D. (Engineering).
Nagata Daiki
Dentsu Inc.
Data & Technology Center
Responsible for advertiser projects, logic development, and data analysis utilizing a People Driven DMP primarily on STADIA. Engaged in the development of Radio Dots, a solution based on Radiko listening log data. Currently on assignment at DENTSU CROSS BRAIN INC. Master of Engineering.