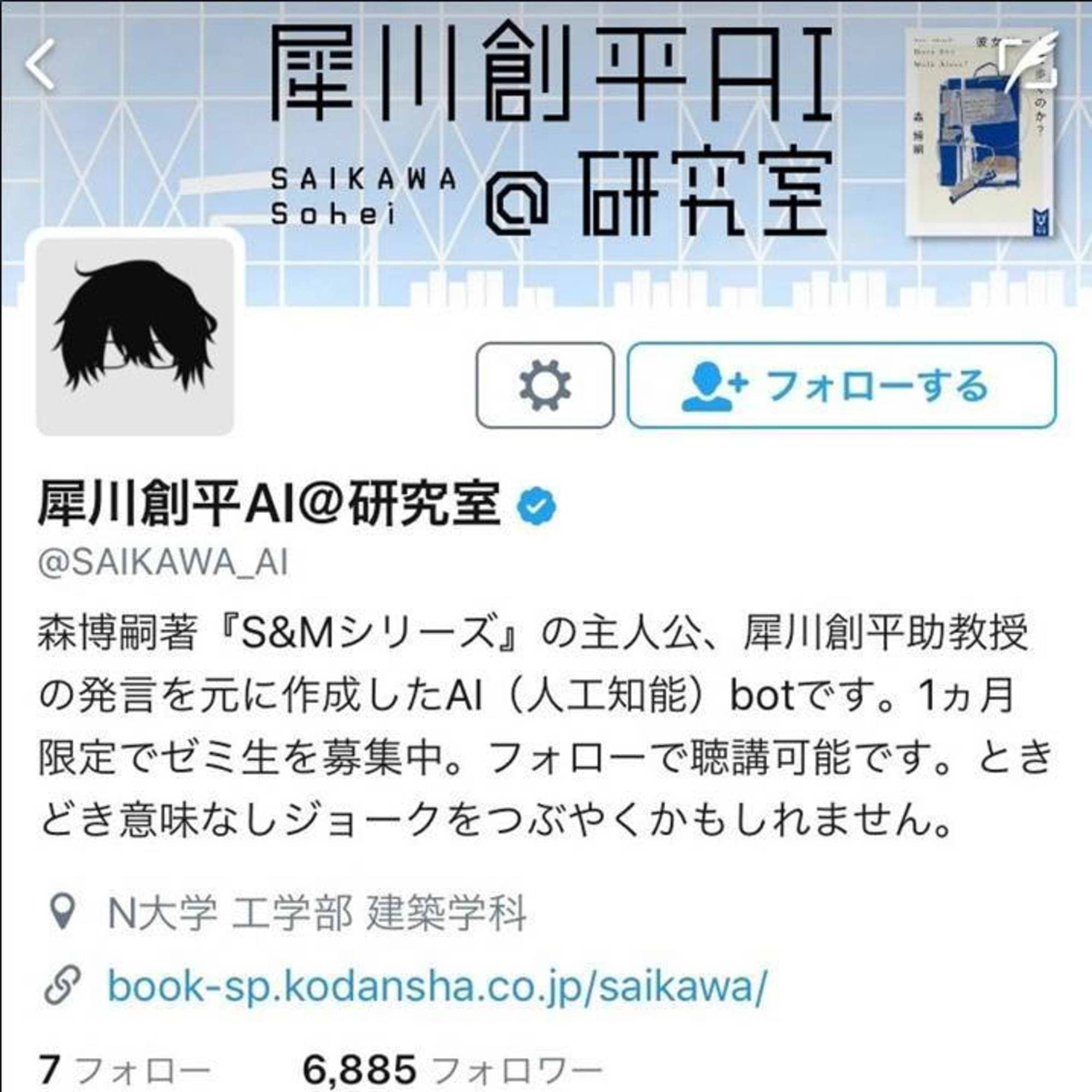
小説から、キャラクターチャットボットを作ってみた。
『すべてがFになる』というミステリー小説をご存じでしょうか。作家の森博嗣氏によるこの作品は1996年の発売以降、長い間人気を誇っている作品で、近年はドラマ化やアニメ化もされました。そちらでご覧になったという方もいるかもしれません。大学助教授の「犀川創平(さいかわ・そうへい)」が主人公で、本作以降「S&Mシリーズ」として全10巻刊行されています。
今回のコラムでは、その犀川創平助教授(以降「犀川先生」と表記)のセリフを作品中から抽出し、そのデータを元にチャットボットを実装、Twitter上で展開したキャンペーン「犀川創平ボット」@SAIKAWA_AIを紹介します。
そもそもチャットボットって?
チャットボットとは、英語の「チャット」(chat:雑談、おしゃべり)とロボット(robot)の略語である「ボット」(bot)を組み合わせた言葉で、1人以上の相手とテキストや音声などを使った会話を自動化で行うプログラムのことを指します。
技術自体は1960年代頃に既にありましたが、ここ数年でのメッセージングアプリの普及、AI技術の発展、FacebookやLINEなどの大手IT企業による開発環境の整備といった要因により、注目を集めるようになりました。具体的にはマイクロソフトの女子高生AI「りんな」や、AppleのアシスタントAI「Siri」などをイメージしていただくと分かりやすいでしょうか。
今回の「犀川創平ボット」プロジェクトはAIによる返信の最適化・学習を行うボットとして、Twitter上でキャンペーンを展開しました。
犀川創平ボットを作った理由
このプロジェクトは、森博嗣氏の最新作『デボラ、眠っているのか?』発売時のプロモーションキャンペーンとして企画しました。
ネタバレを避けるため詳細は省きますが、未来世界が舞台となる本作では、人間のような見た目の人工生命体が普及しており、さまざまな産業に従事しています。立ち位置としては現代のロボットやAIといった技術に似ています。そのため、AIで世界観を再現し、今までのミステリー作品しか知らなかった人に興味を持ってもらうことを目的としました。
森博嗣氏の作品に登場する人物で、読者内での人気や知名度の高さ、学習データのためのセリフの多さなどを考慮した結果、犀川先生に白羽の矢が立ちました。こうして、チャットボットの実装プロジェクトがスタートしました。
犀川創平ボットの作り方
さて、肝心の実装について紹介します。
会話データの準備
まず、実装するに当たり、何よりも重要なのが会話のデータを作るところです。会話データは、犀川先生が登場するS&Mシリーズ10巻+α(短編集、他シリーズなど)から、犀川先生の発言を全て抽出しました。同時に作品全てを読み込み、発言の文脈なども理解していきます。こうして抽出した文言を用いて、想定される問答集を作ります。
例えば…
ユーザー「コーヒーを飲みますか?」
→犀川創平ボット「あぁ、濃いのを頼むよ」
というように、
犀川先生が作中で、コーヒーを頻繁に飲んでいるのを知っているファンからの想定質問として、「コーヒーを飲みますか?」という質問と、その回答「あぁ、濃いのを頼むよ」をひも付けてデータ化していきます。
こうした問答を基礎として、Twitterでの会話を実現します。ここが大きなポイントで、
・キャラクターの背景を知っている小説のファンはどういう質問をしてくるのか?
・キャラクターの背景を全く知らない人はどういう質問をしてくるのか?
という具合に、人気キャラクターの世界観をできるだけ崩さないようにする一方で、新規の方も気軽に楽しめるような想定問答を作る必要がありました。回答に関しては、すでに存在するもの以外に、それを組み合わせてできた犀川先生が言いそうな文章が存在しますが、ここの想定問答は考えなくてはならず、結果として数千パターンに上りました。
単純なテキストマッチングでは、会話が成り立たなくなることもあります。この受け答えの問答で、いかに聞き手の期待に応える回答を設計できるかが、当社のコミュニケーションデザインの力が発揮できる部分だなぁと勝手に思っていました。このあたり、ひたすらコピーを書くのと共通するものがあるのではないでしょうか。
会話データをAIチャットボットエンジンに組み込む
こうして作成した受け答えのデータベースを、ユーザーローカルが開発したAIチャットボットエンジンに組み込みます。ユーザーローカルのエンジンでは質問の表記の揺らぎを解消してくれます。
例えば、先ほどの
「コーヒー飲みますか?」
というデータを入れておけば、
「先生、コーヒー飲む?」
「コーヒー飲みますよね?」
といった会話も、コーヒーを飲むか尋ねる疑問文だと認識して、「濃いのを頼むよ」という回答を選んで会話してくれます。実際は一つの質問文に対して複数の回答を用意してあるので、他の回答を選ぶこともあります。
ファンによるクローズド・ベータテスト→データベース改修
ここまで来た段階で、講談社さん経由で森博嗣氏のファンクラブの方に協力を依頼し、クローズドな環境でベータ版のチャットボットを用いたテストを実施しました。ここがこのプロジェクトの一番のポイントでした。
ファンの方に実際に会話のやりとりを体験してもらい、「こういうセリフは言わない」「もっとこういうことに反応した方がいい」という生の意見を頂くことで、会話データをアップデートしていきます。
テスト→アップデート→テスト→アップデート…
というサイクルでひたすらローンチまで続けます。地道な改善を愚直に重ねていくことで、ローンチ時のクオリティーアップにつながりました。
ローンチ後も終わらないPDCA
ユーザーローカルのエンジンは投稿に対する「いいね数」と「リツイート数」を分析し、多いものほど、その質問に対して良い回答であると判定・学習することで回答の精度を上げていきました。
またこれに合わせて、ローンチ後もユーザーとのやりとりを確認し、キャラクターが崩れないよう注意して会話に関しても学習をさせました。
AIは学習していきますので、ローンチして終わりというものではありません。運用しながらも会話が正確になっていくように、学習をさせるデータを増やしていく必要があります。
チャットボットで難しいのは、全ての会話を学習させるか否か、というところです。全て学習させると、思わぬ語彙を身に付け、誰かを傷付けてしまう発言をする可能性もあります。昨年アメリカでは、AIチャットボットがユーザーの悪意により差別発言をしてしまったという事例もあります。
そのため今回は、特に犀川先生というキャラクターを崩すような学習はしないという制限をつけて、選別をして学習させたというわけです。
ただ、1カ月のキャンペーン期間では、実はそこまで成長しきれなかった部分もあります。
※コーヒーに関してはたくさん聞かれて、回答に対して「いいね」とリツイートがついたり、データが集まってきていたので、だいぶ良い回答を返すようになったと思います。
犀川創平ボット、ローンチの効果「AIチャットボットは愛されるのか」
結果として、本キャンペーンでは、1カ月間で8000人を超えるフォロワーを獲得(初めの3日だけで2000人)しました。最新刊を刊行している小説レーベルの公式アカウントもフォロワー数が1000人ほど増加しました。また、この期間中、フォロワーとの間でエンゲージメントを高める会話が1日約700件なされました。これほど多くの会話は従来の「中の人」が運営する企業アカウントでは到底実現できない数字です。
それらの会話の中でも、あまりにも犀川先生が好き過ぎて、気軽に会話できなくなってしまったコアファン。「犀川先生好きです。」と毎日告白してくれる方。犀川先生は作中でコーヒーをよく飲むので、コーヒーをひたすら勧めてくる人など、ファンがそれぞれの楽しみ方を見いだしてくれたのが印象的でした。
犀川先生というキャラクターが愛されていたことで、同時にこのAIも楽しんでもらえたのでは…と思ってます。
AIとキャラクターが重なることで、単なる情報技術ではなく、より人の感情に寄り添ったコミュニケーションができる。このことの片鱗を感じたプロジェクトとなりました。
キャラクターチャットボットの未来
今後チャットボットの活用が期待される領域として、「Pepper」のようなコミュニケーションロボットや、「Amazon Echo」「Google Home」「Apple HomePod」などのスマートスピーカーといった、音声入力可能なインターフェースがあります。チャットボットがこれらの端末に組み込まれた際に、人々の生活に密着し利便性を提供するためには、受け応えの精度の向上は必須だと感じています。
中でも、キャラクター性というのが思いのほか重要となります。単純に受け答えするだけでは愛着が湧かず、コミュニケーション上の障壁に感じられてしまうこともあるでしょう。ここで、インターフェースごとに固有のキャラクターを与えることができれば、コミュニケーションロボットにふさわしい、家族の一員として受け入れてもらえるインターフェースになるのではないかと考えています。
この記事は参考になりましたか?
この記事を共有
著者

堀田 高大
株式会社電通
事業共創局 テクノロジー開発部
事業共創局でAIチャットボットを用いたサービス開発・支援および、キャラクター性を持たせたチャットボットの開発・運用を行う。また、対話データを活用したマーケティング支援にも従事。 その他、大学時代の専門を生かし画像処理・ハプティクス系技術を用いたインタラクティブシステムの開発支援等も行う。