画像生成AIはクリエイターを脅かすのか、それとも。

2022年夏は、AI史において大きなターニングポイントになるかもしれません。
こんにちは。電通グループのAI活用を推進する「AI MIRAI」統括の児玉です。今日は大きな話題を生んでいる、画像生成AIについて考えていきます。
7月のDALL·E2(※1)のβ版公開に始まり、8月のMidjourney(※2)、StableDiffusion(※3)と、相次いで画像生成AIサービスがリリースされ、その多くは無料、もしくは多少の利用料で誰もが活用できるため、大きなニュースとなっています。
※1 DALL·E2 = 米OpenAI社が開発したテキストから画像を生成するAIモデル。
※2 Midjourney = 米Midjourney社が開発したテキストから画像を生成するAIモデル。Discord上で稼働する。
※3 Stable Diffusion = 英Stability.ai社が開発したテキストから画像を生成するAIモデル。オープンソース化されている。
またStable Diffusionはオープンソース化されていることから、公開当初からカスタマイズ版が登場したり、その他のサービスへの組み込みが検討されるなど、さらなる広がりを見せています。これを執筆している8月末時点でも、毎日何かしら新しいサービスの情報が入ってきており、祭りの様相を呈しています。
これらの画像生成AIを用いると、今までイラストが苦手であった人も簡単に、自由に絵を描いたり、高度な合成技術が必要だった写真素材を生成できるようになります。それにより、イラストレーターやデザイナーの仕事は奪われていくのでしょうか。そして私たち広告業界、クリエイティブ業界の仕事はどう変わってくるのでしょうか。
ここでは、今見えている技術だけでなく、少し先に訪れるであろう変化まで踏み込んで、考えてみたいと思います。
テキストの入力だけで、高い精度の画像を生成
未来のことを考える前に、まずは今できることを確認しましょう。
先に挙げた3つのサービスはいずれも、「テキストから画像の生成」をするツールです。例えば、「東京上空に訪れる巨大UFO」などのテキスト(プロンプト 。システムに動作を促すもので、俗に呪文などと呼ばれています。)を入力すると、このような画像が、1分もたたずに生成されます。現時点では ほとんどが英語にしか対応していませんが、AIにより英訳もあっという間になりましたね。

それぞれのAIによる得意不得意は多少あるものの、一部の不自然な個所を除けば、ぱっと見はプロのイラストレーターの仕事と遜色ないほど高度な画像が生成されます。現時点ではイラストのほうが得意なようですが、写真の生成も可能で、例えば「バーでマティーニを飲むロボットの白黒写真」などは以下のとおり生成されます。

AIはさまざまな画像と言語を同時に学習しているので、プロンプトを工夫することで、より狙った画像に近いものや、精度の高い画像を生成することができます。例えばプロンプトの最後に「4K」をつけたり、雑誌の名前を入力したりすることで、4K画像のような、あるいはその雑誌に掲載されるような、より精度の高い画像を生成できるのです。
重要なポイントは「基盤モデル」と「オープン化」
しかし私たちは、これらのAIの与える影響は、「イラストを簡単に生成できる」にとどまらないと考えています。将来的な影響を考えるうえでのポイントは、これらのAIが「基盤モデル」であること、そして「オープン化」の流れという2点になります。
まずは「基盤モデル(foundation model)」についてです。技術的な詳細は割愛しますが、これはざっくり言うと「とにかく大量のデータを学習することにより、特定用途ではなく、さまざまなタスクに対応できるAI」となっています。
従来のAIの多くは、ある単一の目的(タスク)に沿ってデータを学習し、出力するというものでした。例えば「英語と日本語の組データを学習させれば機械翻訳ができる」などです。しかし近年の基盤モデルには、「とにかく大量のテキストデータを学習させることで、クイズから翻訳からプログラミングまで、テキスト関連なら何でもできる」という汎用性の高いモデルも増えてきています。
さらにここ数年 はテキストデータにとどまらず、大量の画像や音声なども学習することにより、データ形式をまたいだ タスクが可能になっています。今回の画像生成AIはまさに、この基盤モデルの機能のひとつ、というわけです。
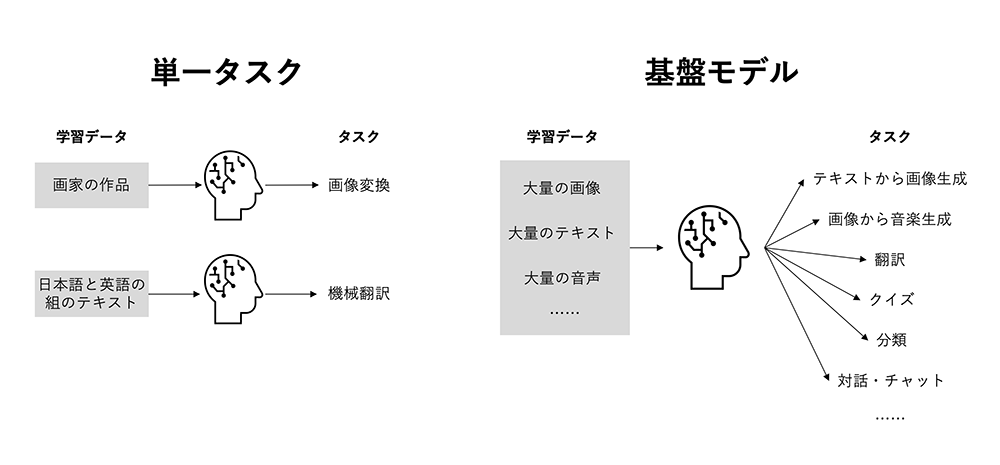
ということは、今後は画像に限らず、さまざまなデータの生成が可能になるでしょう。例えばテキストによる入力で音声や音楽を生成したり、3Dモデルや動画なども徐々に扱えるようになってきています。
もう一つは「オープン化」の流れです。
これら基盤モデルへの取り組みは、何年も前からありましたが、今回画期的なのはそれらが安価もしくは無料で、学習データごと公開されたことに尽きます。
基盤モデルの構築には、何十億・何百億という大量のデータと計算資源が必要になります。今まではOpenAIやGoogle Researchをはじめとする大手の研究機関がほぼ独占して開発を行い、商用利用は制限されてきました。
しかしこの夏、それらが公開されたことで、今までにないサービスが次々と生まれて きています。そして先にお話しした通り、基盤モデルの機能は画像生成にとどまりません。今後さまざまな機能が、誰でも使えるようになってくるはずです。
多種多様なAIが同時多発的にあらわれる、まさにカンブリア爆発です。

今後生まれてくるであろうサービスと注意したい点
これらの流れを考えると、今後数カ月から数年で、多くのサービスが生まれてくるのではないでしょうか。例えば、こんなサービスが生まれるかもしれません。
- 音声まで扱えるようになり、「テキストの入力から、SE(効果音)や音楽を生成する」あるいは「写真や動画から、最適なBGMを生成する」なども可能になる 。
- 動画や3Dモデルも静止画の延長線上になるため、メタバース上のオブジェクトやアバター、ちょっとした動画なども生成できるようになる。
- 新しいイラストを描くだけでなく、既存のイラストや写真を拡張したり、背景とオブジェクトをなじませる(合成する)なども可能になる。
- テキスト生成も今以上に自然になってくるため、画像を読み取って適切にコメントしたり、さまざまなデータから得られる知見を自然な文章でレポート や記事にする。
実際、上記のうちほとんどは、すでに技術は開発されており、遅かれ早かれ実装されていくものです。
そして、オープン化の流れを考慮すると、それらが単独のサービスではなく、すでに私たちが使用しているサービスに搭載されてくるでしょう。普段操作しているオフィスソフトやクリエイティブアプリに、多様な生成機能が搭載される日も近い、と感じます。
一方でこれらのツールの開発と利用には、法的・倫理的な制約が必要になって きます。
例えば著作権。AIによって生成された成果物は、現状ではAIを操作した人に創意工夫が認められれば、著作権はその人に付与されることになっています。しかし技術の進歩に応じて、ここの考え方は今後議論され、大きく変わる可能性があります。法整備が追いつかない領域であるがゆえに、盗作や剽窃などの悪用を未然に防ぐためのシステム側の仕組みも重要になります。
また、学習データや出力の偏りをあらかじめ考慮し、DE&I(ダイバーシティ・エクイティ&インクルージョン)への配慮や、著名人やキャラクターを扱う場合などにも注意が必要です。

現状のAIはDE&Iへのバイアスが削除できていない。「消防士」と入力すると、女性は出てくるものの、いずれも白人である。
法理解、バイアスの認識、その他の倫理的課題を理解することも、AI時代を生きる私たちに求められてくるのです。
クリエイティビティはどう変わるのか?
さて、ようやく本題に到達しました。これらの画像生成AI(あるいは基盤モデル)は、広告業界におけるクリエイティブの仕事をどう変えるのでしょうか。
ひとつの流れとして、AIを活用して制作・創作をスムーズに行うという業務プロセスが一般化するでしょう。翻訳の世界では、「すべて人間」でも「すべてAI」でもなく、「あらかじめAIが翻訳し、人間が細部を整える」というかたちで、短時間かつ正確に翻訳するサービスが登場しています。同じように、粗い部分をAIが行い、仕上げを人間のデザイナーが行うのも当たり前になりそうです。実際、すでに電通グループ内では、提案資料やイメージ図にこういったツールを活用しはじめていますし、基盤モデルを活用した広告生成の研究開発も進めています。
そして、クリエイターにテクノロジーへの理解も求められてきます。動きの速いテクノロジー業界にアンテナを張りながら、今の技術では何が可能なのか、少し先に何が可能になるのかを見極め、新たな顧客体験を設計したり、自分たちが使うツールを進化させる必要があります。技術力とクリエイティビティが今まで以上に不可分なものとなってくるでしょう。
最後に、これらのAIはすべてツールでしかありません。広告業界だけでなく、イラストレーター、作家、写真家など人間 のクリエイターには、より本質的な洞察力が求められます。AIによる生成が一般化していくにつれ、単なる美しいイラストや動画には、人々は感動しなくなっていくかもしれません。どのような表現をすれば、どのような文脈をつくれば人々の心を動かせるのか、新しい表現の地平を常に探りつつけることが、人間の使命となります。

Generated by Stable Diffusion
私は、生成系AIの普及は「カメラの発明」のようなものだと考えています。1800年代にカメラが登場し、徐々に普及してくると、単に写実性だけを売りにしていた風景画家や肖像画家たちは職を失っていきました。実際当時のフランス美術アカデミーの重鎮であったドミニク・アングルは、写真撮影を禁止するよう政府に働きかけたと言われています。
一方で、その危機感が画家を写実性から引きはがし、印象派の誕生を促し、抽象絵画につながる近代絵画の発展を促したとされています。さらに、カメラという新しいテクノロジーを用いた「芸術写真」という新たな芸術ジャンルも切り開かれていきました。アーティストたちの表現の幅は、カメラというテクノロジーの黒船をきっかけとして、大きく広がっていったのです。
そう考えると、これらのAIの発展も、多様な問題をはらみながらも、最終的にはクリエイターが活躍できる幅を大きく広げるきっかけになるはずです。私たちはこれからも、テクノロジーの動向を見定め、ときに先導しながら、社会に対して新しい価値と体験を提示していきたいと思います。


この記事は参考になりましたか?
この記事を共有
著者

児玉 拓也
株式会社 電通グループ/dentsu Japan
グループAI戦略チーム /主席AIマスター
デジタルプラットフォーマーなどのクライアント担当プロデューサーとして活動したのち、2018年からAIの活用を社内外で推進。 現在は株式会社電通グループに所属し、日本のみならず海外も含めた電通グループ全体のAIとテクノロジー戦略に携わっている。

