アンケートから社員の潜在意識を見抜く、「MINUKERU」の実力とは?
アンケートや口コミなどのテキストデータを、もっと解像度高く、スピーディに分析できたら……。
電通は、大阪大学大学院経済学研究科 勝又壮太郎教授と共同で、テキストデータから、通常の分析では見えない「文脈」を抽出するデータソリューション「MINUKERU」(※1)を開発し、2024年6月にローンチしました(リリースは、こちら)。
本連載では事例を交えながら、「MINUKERUでテキストデータをどこまで見抜けるのか?」に迫ります。
※1 MINUKERUは、電通側でデータを分析し、その結果に関するレポートをクライアントに納品します。また、その分析結果に基づいて、電通側で施策立案なども可能です。
MINUKERUで見えてくる潜在文脈
某エンジニアリング会社の社員に、「自社のどのようなところに魅力を感じて入社したか」を聞きました。
回答(自由に記述)を従来のテキストマイニング(※2)によって分析すると、以下のようなワードクラウド(特徴的なワードほど、フォントが大きく出てきます)がアウトプットされました。「製品」「開発」「貢献」「雰囲気」「環境」など、キーワードとなりそうなものは多く出てきているものの、どのような文脈で自社に魅力を感じたのか、このアウトプットのみでは、なかなか解釈がしづらいと思います。
※2 テキストマイニング:テキストから単語を抽出し、それらの出現頻度や共起関係などを分析して有用な情報を抽出する手法。

一方、MINUKERUでは「トピックモデル(※3)」という統計手法を活用することで、アンケートの回答から、いくつかの文脈を抽出することが可能です。
※3 トピックモデル:文章データのトピック(主題)を判断する自然言語処理の手法。

「TOPIC1」のワードクラウドを見ると、「雰囲気」「働く」「環境」が大きく表示されているので、「働く環境や社の雰囲気」に魅力を感じた、と解釈できそうです。
「TOPIC2」は、「開発」「貢献」「ツール」「自動車産業」というワードから、「ツールの開発によって、自動車産業に貢献することができる」と解釈できます。
「TOPIC3」や「TOPIC4」も同様に解釈すると、それぞれ「自動車業界における自社の技術力や製品力」「安定性や自己成長に期待できるところ」が魅力ポイントと考えられます。
従来のテキストマイニングより、文脈の解釈がしやすくなったと思います。このように潜在文脈を引き出せるのが、MINUKERUの特長の一つです。
MINUKERUはどのようなテキストデータに対しても分析が可能ですが、特に回答者一人当たりの文字量が多めになりそうな質問との相性が良さそうです。
前述したような、自社に関する社員アンケートは、良くも悪くも赤裸々な思い・意見をやや長めに述べた回答が集まりがちです。そのぶん、大変示唆に富んだ結果が抽出されやすくなります。
他には、コールセンターに寄せられるお客さまの声の分析にも向いています。コールセンターのお客さまの声はテキストデータ化できます。お客さまとは、ある程度やり取りが生じることがあり、一人当たりのテキストデータが多くなる点で、相性が良いでしょう。
一方、視聴者からのCM評価のような、「おもしろい」「つまらない」「かっこいい」といった、短めの回答にとどまりがちなものは、示唆に富んだ結果が抽出されにくくなることが考えられます。
潜在文脈別に、社員の特性をとらえる
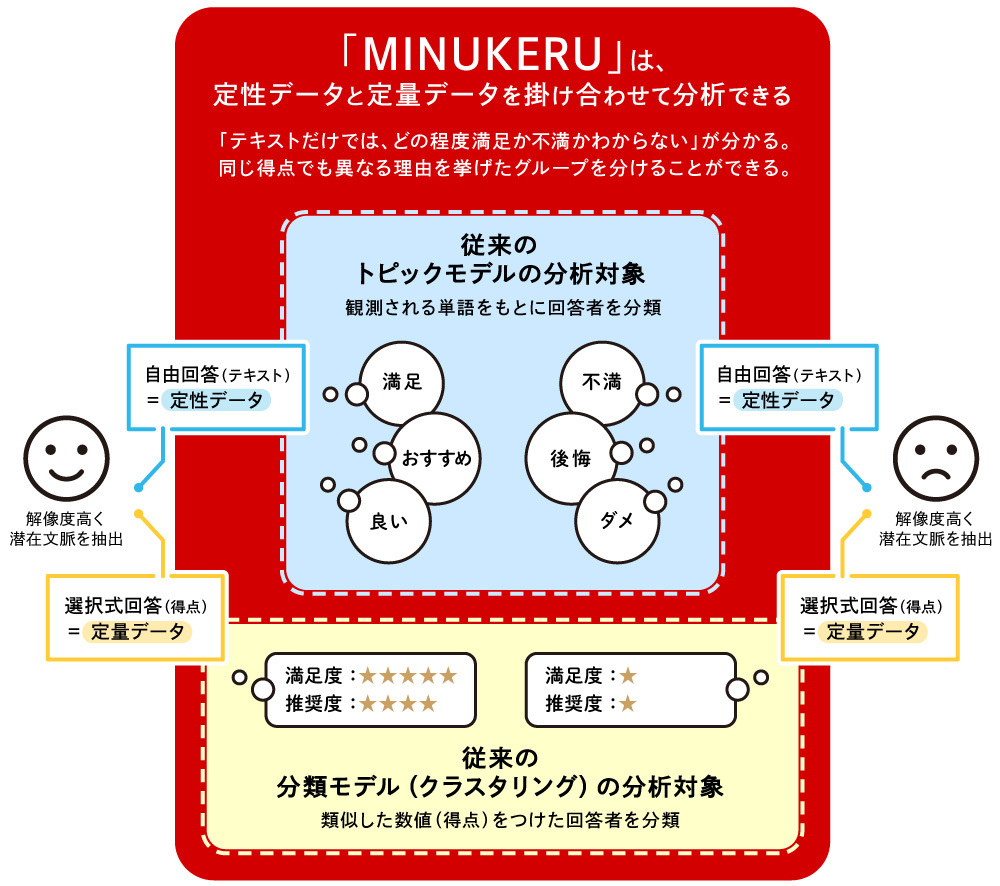
MINUKERUの大きな特長は、従来のトピックモデルをさらに発展させて、定量データも加味して分析できることです(※5)。テキストデータのみでは、出てくる文脈がポジティブなのか、ネガティブなのかが分かりづらいこともあります。そこに定量データでの評価を入れ込むことで、ポジネガも分かるようになります。
また、定量データで同じような評価(例:「上司との関係が良い」が高得点)をされていても、いくつかの文脈に分けられることもある(例:「話しやすい」「しっかり指導してくれる」など)ので、そのような文脈の抽出も可能です。
※5 Katsumata, S., & Takahashi, K. (2024, July 27-29). A Combined Topic Model for Unstructured and Structured Data. The 46th ISMS Marketing Science Conference, Sydney, Australia.
前述したエンジニアリング会社のアンケートの話を続けます。MINUKERUは定性データ(今回の例では自由回答データ)に基づいて、「社員AさんはTOPIC1」「社員BさんはTOPIC3」といったように、社員一人一人をクラスタリングしています(※6)。ここが定量データに基づくクラスター分析との違いです。
エンジニアリング会社の社員アンケートでは、自由回答データ以外にも、社の風通し/雰囲気、裁量権、社内制度、人事制度などに対するイメージや、デモグラ(年代、入社年次、管理職かどうか)なども定量的に聴取しています。
これらのデータをもとに、各TOPICに所属している人が、どの定量項目が高いのか低いのか、また、デモグラ観点で、各TOPICに属している社員がどのような方なのかも評価できます。これは、クラスター分析で、クラスター別に定量項目をクロス集計するのと、ほぼ同様です。以下が実際の結果です。
※6 クラスタリングする時点でも定量データを踏まえていますが、内容が複雑なため、ここではその詳細を割愛します。
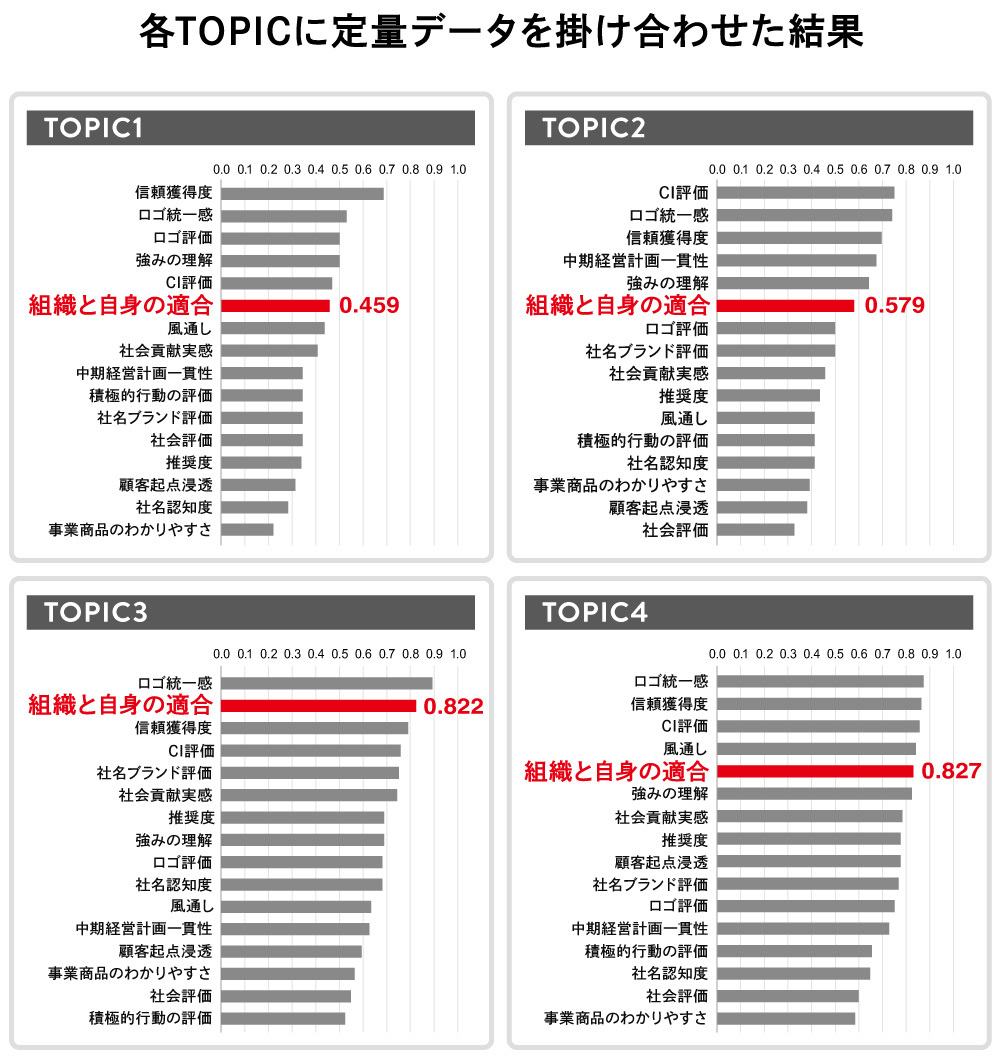
社員のエンゲージメントという観点では、「組織と自身の適合」の指標が重要だと思います。TOPIC4のスコアが最も高く、TOPIC3もスコアが高くなっています。それに対して、TOPIC1は、他のTOPICよりもスコアが低く、項目の順位も下位になっています。
このような結果を見ると、「それぞれのTOPICに所属している社員はどのような人たちなのか?」ということを知りたくなるでしょう。今回の調査では年代、入社年次なども聴取していて、どのような社員なのかも見えてきます。以下がその結果です。
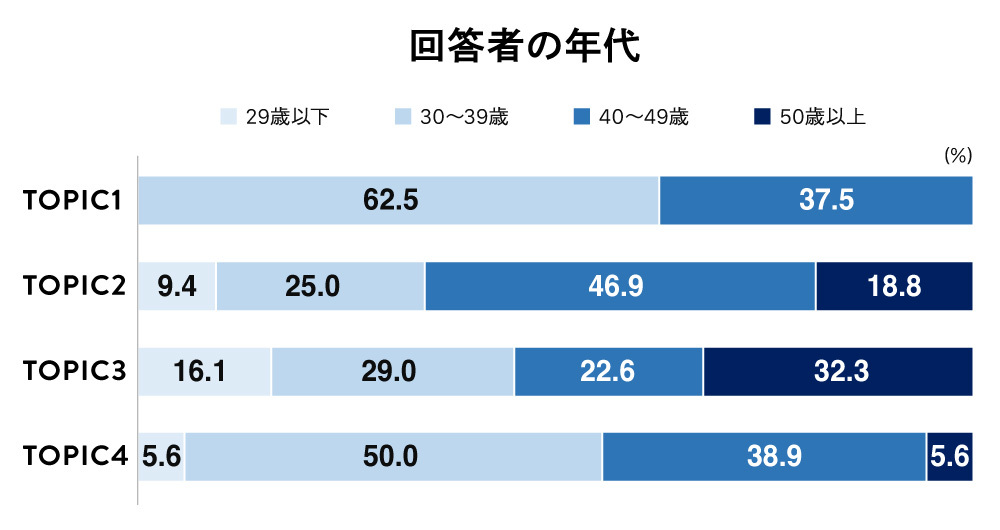
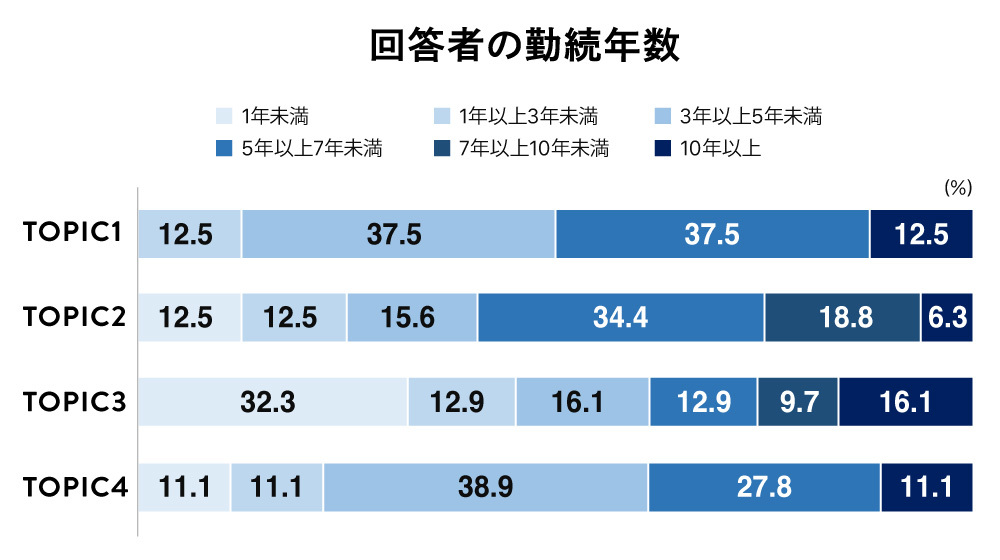
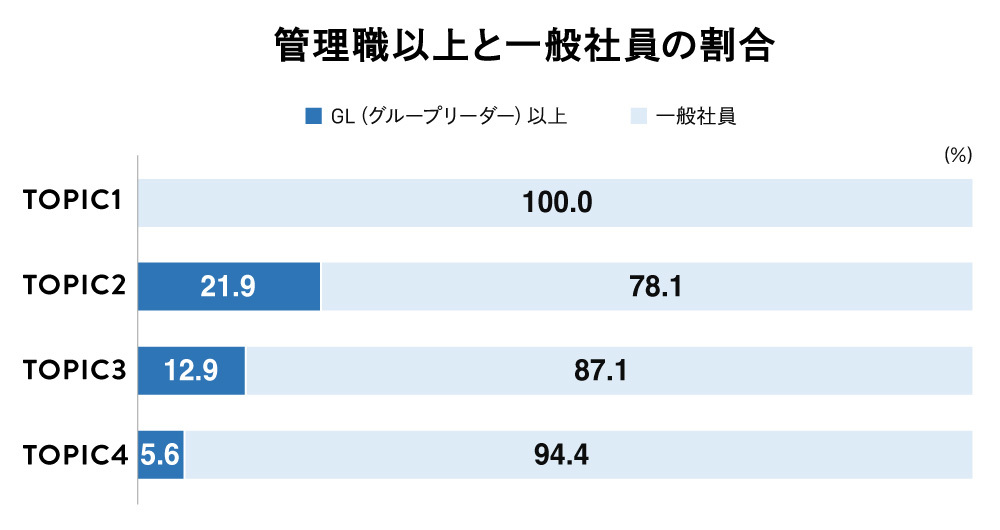
社に対する評価が全体に低かったTOPIC1は、30~40代、かつ、勤続年数が1年以上~5年未満と、この企業での業務に徐々に慣れてきたと思われる社員が多い傾向です。この結果を同社の経営企画室に提示しました。同社は3年くらいで退社される社員が散見されるそうで、「こういった方々がまさにTOPIC1だと思った」という意見をいただきました。
一方で、社に対する評価が高かったTOPIC3・4の社員のデモグラを見ると、TOPIC3は50歳以上、勤続年数は7年以上の社員の割合が高くなっており、マネジメント層も多めなようです。TOPIC4も勤続年数は長めですが、30~40代がほとんどを占めます。
このことから一つの仮説として見えてくるのは、同じ年齢層でも勤続年数が多い方が社に対する評価が高くなり、よって、勤続年数がまだ短めな社員を如何に離脱させないかが重要になってきます。
同じような年代でも、勤続年数の違いでどのようなエンゲージメント文脈で差異が生じているのかは、今回のデータでは深掘りできませんが、例えば、社員への個別インタビューなどを実施することで、こういった深掘りがさらにできるでしょう。
今回はある会社のアンケート回答分析の事例を紹介しながら、MINUKERUの特長を紹介しました。テキストデータの主題を解像度高く読み解き、そこに定量データを加味することで、テキストデータの内容をより見抜けるようになることがご理解いただけたのではないかと思います。
MINUKERUについて、さらに詳しく知りたい方は下記までご連絡ください。
Email:minukeru@dentsu.co.jp

この記事は参考になりましたか?
この記事を共有
著者

高橋 一樹
株式会社電通
第2マーケティング局
マーケティング・コンサルタント
データを基点としたソリューション提供(データ分析、データドリブンPDCAなど)を得意とする一方、近年は企業/ブランドコンサル、インナーブランディング、ビジョン規定、事業/マーケティング戦略策定、デジタルマーケティングコンサル/トランスフォーメーション、営業支援、ビジネス開発など、さまざまなソリューション提供に従事。博士(社会工学)。

