Note: This website was automatically translated, so some terms or nuances may not be completely accurate.
March 3rd is "Ear Day." Hearables free up your "eyes" and "hands."
Today, March 3rd, is "Hinamatsuri" (Doll Festival). But I strongly want to emphasize that it's also "Ear Day"! It's not just because "33" can be read as "mimi" in Japanese, nor simply because the shape of "33" resembles an ear.
Alexander Graham Bell, known for inventing the telephone, was also someone who dedicated his life to deaf education. Bell's birthday was March 3rd. It was also on March 3rd that, through Bell's mediation, Anne Sullivan came to Helen Keller. Don't you feel a fateful connection between March 3rd and "ears"?

In previous installments, we've referred to "hearables" as "Hear+Wearable" (wearable devices for hearing). However, they can also be interpreted as "Hear+Able" (technology that enhances hearing). This unique interpretation includes not only devices worn on the ear but also the technology itself that complements human hearing within the broad definition of hearables.
Even Bell's invention of the telephone could be seen as a functional extension enabling "remote communication of hearing (voice)," making it perhaps the original "hearable." So, how far has "hearing technology" advanced today? This time, we focus on introducing it from a software perspective.
"mimi" – Identifying People by Their Voice Alone
Woman in her 30s: "Have a good day!"
A-kun: "What should we do when I get home today?"
(sneeze)
B: "I think I might be catching a cold."
(Cough, railroad crossing sound, train sound, car sound)
Man in his 40s: "Hurry up or I'll close the gate!"
(Cheers, screams, laughter...)

This is an example image of children going to school, automatically transcribed from microphone audio using the "mimi" service. mimi is an "auditory" platform developed by Fairy Devices, a venture company originating from the University of Tokyo. It takes audio data and processes it in various ways before sending it back. A key feature of mimi is "speech recognition" technology (STT = Speech to Text), which converts speech into text that computers can process.
Many people now use voice input for searches, a practice made possible by the recent improvements in speech recognition accuracy. Currently, numerous companies are fiercely competing to enhance speech recognition accuracy by leveraging a technology called "deep learning." Beyond this fundamental STT technology, mimi incorporates a mechanism that distinguishes "who is currently speaking" by pre-registering individual voices. It can also estimate the gender and age attributes of unregistered speakers. Furthermore, it provides systems to recognize non-conversational sounds like "clapping," "breathing," "sneezing," and "laughter," as well as non-human sounds like trains and cars.
In other words, if you leave the microphone on and continuously record ambient sounds, it automatically logs "who said what, in what situation" as a life log, which you can later search via text. It's essentially the ultimate form of meeting minutes. I once spoke with Mr. Masato Fujino, President of Fairy Devices. He mentioned that when he reviewed his own audio life log recorded with mimi, it "felt like a script with stage directions, and I was the protagonist of that story."
In recent years, as an extension of "visual" capabilities, attribute estimation technology using image recognition (like Facebook's face recognition) has gained attention. Similarly, technology for identifying and inferring situations and individuals based solely on "sound" has also advanced significantly.
Voiceprint authentication for online payments—no password needed!? The near future seen in "Nina"
A man speaks into his smartphone.
Tom: "My voice is my password. Can you transfer $500 to my wife's account?"
Smartphone: "OK, accepted. Tom, would you also like to pay the overdue cable bill?"
Tom: "Right. Pay them all."

This is "Nina," a service from Nuance, a global leader in speech recognition based in the United States.
Until now, internet payment transactions required passwords. However, by pre-registering a keyword using your own voice, Nina can identify you simply by hearing that keyword afterward (in the video, "My voice is my password" serves as the keyword). This means the "password entry" that has long troubled us becomes unnecessary.
While voiceprint authentication technology is being developed by various companies, Nuance had already released this video back in 2012 (five years ago!). When I first saw this video, I was amazed by the vision of a world without wallets or the need to remember passwords. I also sensed the potential for communication to change dramatically with hands-free input.
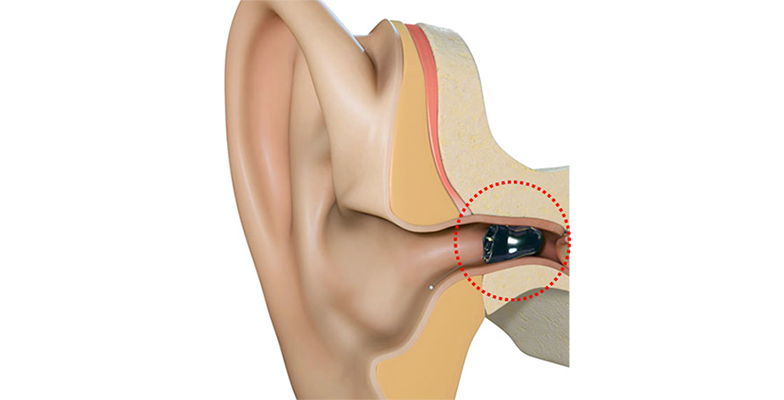
I also thought, "Couldn't such payment services eventually be done without a smartphone, just using wireless earbuds with a microphone?" Currently, biometric payment methods include various attempts like fingerprint recognition, facial recognition, and vein recognition. Financial services like payments cannot tolerate errors, inevitably requiring double or triple authentication, which tends to burden users. However, combining voiceprint authentication like Nina's with the "biometric authentication using sound and ear canal shape" introduced in Part 2 would allow capturing two biometric factors (ear canal shape and voiceprint) using only a microphone and earbuds. This would significantly reduce user burden and bring us much closer to "sound-only payments."
Hearables will once again free people's "eyes" and "hands"
We've seen two examples demonstrating how "advancements in AI technology have pushed computer speech recognition capabilities this far!" Current software can now accurately transcribe and understand human speech, as well as precisely identify who is speaking. Given this progress, we can expect an increase in hands-free, voice-based computer operation—moving away from the traditional method of visually interacting with devices and manually inputting information (sometimes already referred to as "voice computing"). Much of the everyday communication between humans and machines, which has relied solely on "eyes and hands" for decades, could potentially be replaced by the more convenient "ears and mouth" in the future.
If that happens, the world's landscape should change a bit. If we can handle some of the communication we currently do with "eyes and hands" on smartphones – like checking email, using social media, managing schedules, searching, or getting directions – using "ears and mouth," humans will regain the freedom of their "eyes and hands." Walking while using a smartphone is dangerous, right? It's a state where your "eyes and hands" are occupied by a device. Naturally, it's safer to keep your eyes on the road ahead while holding your child's hand and letting headphones guide you. I'm certainly not downplaying the importance of vision. Rather, precisely because "eyes and hands" are crucial for humans, I believe we should return to how things should be. What kind of future awaits when humans return to their natural state... that's a topic for another time.
Was this article helpful?
Share this article
Newsletter registration is here
We select and publish important news every day
For inquiries about this article
Back Numbers

Author

Nitō Fumi
Dentsu Inc.
Business Development & Activation Division
Currently responsible for solution development utilizing "accelerating technologies," primarily AI, at Dentsu Live Inc. Visiting Researcher at the Japan Marketing Association. Following the 2016 JAAA Gold Prize for the paper "The Advertising Industry Moves at the 'Great Divergence' of the AI Revolution: Next-Generation Agents That Move People" (marking consecutive gold prizes from the previous year), has delivered numerous lectures and contributed articles on AI and cutting-edge technologies. Received the "Japan IBM Prize" at the 2017 Dentsu Watson Hackathon.

